Навигация
Дополнительные параметры
Вы используете устаревший браузер. Этот и другие сайты могут отображаться в нем неправильно.
Необходимо обновить браузер или попробовать использовать другой.
Необходимо обновить браузер или попробовать использовать другой.
Стержневая тема Диалога
- Автор темы Стержень
- Дата начала

Отвары и эликсиры из хвои(символ вечной жизни). Также 50/50 клюквы и кладбищенской ягоды(рябины или малины)перетереть. называется *живая/мертвая вода*. принимать по ложечке и ощущениям.
Вопрос: Если между отдельными нейронами не могут существовать квантовые кореляции то могут ли они существовать в структуре самого нейрона? Это уже к вопросу о мозге-квантовом компьютере (то о чем говорит Пенроуз)
Ответ: Мочь-то могут, а вот повлияют ли на что? Скорей всего, нет. Пенроуза на эту тему лучше не слушать. Он очень плохо поступил: обычно такие гипотезы высказывают для учёной аудитории, получают критику, и всё, дело закрыто. А он вынес гипотезу на широкую публику, неспециалисты не могут грамотно гипотезу раскритиковать, зато заражаются идеями, не имеющими реально обоснования и ценности.
Ответ: Мочь-то могут, а вот повлияют ли на что? Скорей всего, нет. Пенроуза на эту тему лучше не слушать. Он очень плохо поступил: обычно такие гипотезы высказывают для учёной аудитории, получают критику, и всё, дело закрыто. А он вынес гипотезу на широкую публику, неспециалисты не могут грамотно гипотезу раскритиковать, зато заражаются идеями, не имеющими реально обоснования и ценности.
Onigiri делает нейросеть с нуля:
Рекуррентные нейросети

Азбука ИИ: «Рекуррентные нейросети»
Как написать «Войну и мир» и ничего не забыть по дороге
 nplus1.ru
nplus1.ru
Будучи слишком ленивым, чтобы заморачиваться с доступом к тому самому умному ChatGPTbot-у, я таки нашёл способ задавать вопросы его аналогу. Так что, на любой ваш вопрос у меня есть любой мой ответ)) ну, то есть
- если это заинтересовало, то - предлагаю пройти по этой цитате в ту самую тему.
Из послесловия романа "Ложная Слепота" Питера Уоттса:
...
Сенсорный аппарат человека поразительно легко взломать; нашу зрительную систему описывали в лучшем случае как импровизированный набор фокусов. [Ramachandran, V. S. in The Utilitarian Theory of Perception, Ed. by С Blakemore. Cambridge: Cambridge University Press, 1990. p. 346—360.] Наши органы чувств выдают столь фрагментарные и несовершенные данные, что мозг вынужден интерпретировать их на основе оценок вероятности, вместо того чтобы воспринимать напрямую. [Purves, D. and R. B. Lotto. Why We See What We Do: An Empirical Theorv of Vision. Sunderland (Mass.): Sinauer Associates, 2003. 272 p.] Он не столько «видит» мир, сколько гадает о нем. В результате «невероятные» стимулы, как правило, не обрабатываются на сознательном уровне вне зависимости от мощности сигнала. Образы и звуки, не укладывающиеся в нашу картину мира, мы имеем тенденцию попросту игнорировать.
...
Статья: как работает хайповый ChatGPT
+ из другой статьи:
+ из другой статьи:
По заявлениям OpenAl, при создании большой языковой модели GPT-3.5 применялись те же подходы, что и в модели InstructGPT, представленной весной 2022 года.
Основным отличием и преимуществом новых языковых моделей является не столько архитектура (по-видимому, GPT-3.5 недалеко ушла от своей предшественницы GPT-3 с её 175 миллиардами параметров), сколько новый метод обучения, получивший название «Обучение с подкреплением на основе отзывов людей» (RLHF).
Он базируется на участии в обучении нейронной сети множества настоящих людей-учителей, демонстрирующих ей на начальном этапе, как вести диалог. Несколько десятков специалистов вручную сформировали набор вопросов и ответов на них, который «скормили» GPT-3.5 для тонкой настройки модели. Затем они продолжили работу, оценивая генерируемые нейросетью диалоги и ранжируя их по качеству ответов.
Таким образом, внутри GPT-3.5 сформировалось скрытое понимание того, какие ответы люди считают хорошими и правильными, а какие — нет. Благодаря методу RLHF нейросеть научилась имитировать действия экспертов, участвовавших в процессе обучения. В дальнейшем алгоритмы GPT-3.5 обучали сами себя, отталкиваясь от сформированной ранее модели человеческого общения.
Учёные OpenAI отмечают, что настройка больших языковых моделей с использованием экспертных оценок «значительно улучшает их поведение в широком спектре задач», но при этом может приводить к тому, что на неё могут повлиять субъективные особенности конкретных людей, участвовавших в процессе. Поэтому экспертов подробно проинструктировали, как они должны обсуждать с ИИ различные «токсичные» темы.
В процессе обучения текущей версии ChatGPT использовались тексты, созданные до третьего квартала 2021 года. При этом нейросеть не имеет доступа к интернету, чтобы посмотреть актуальные новости, и не может ничего знать о событиях, произошедших после этого. Так что в случаях, когда речь заходит о новостях, система выдаёт некие собственные «версии» на заданную тему.
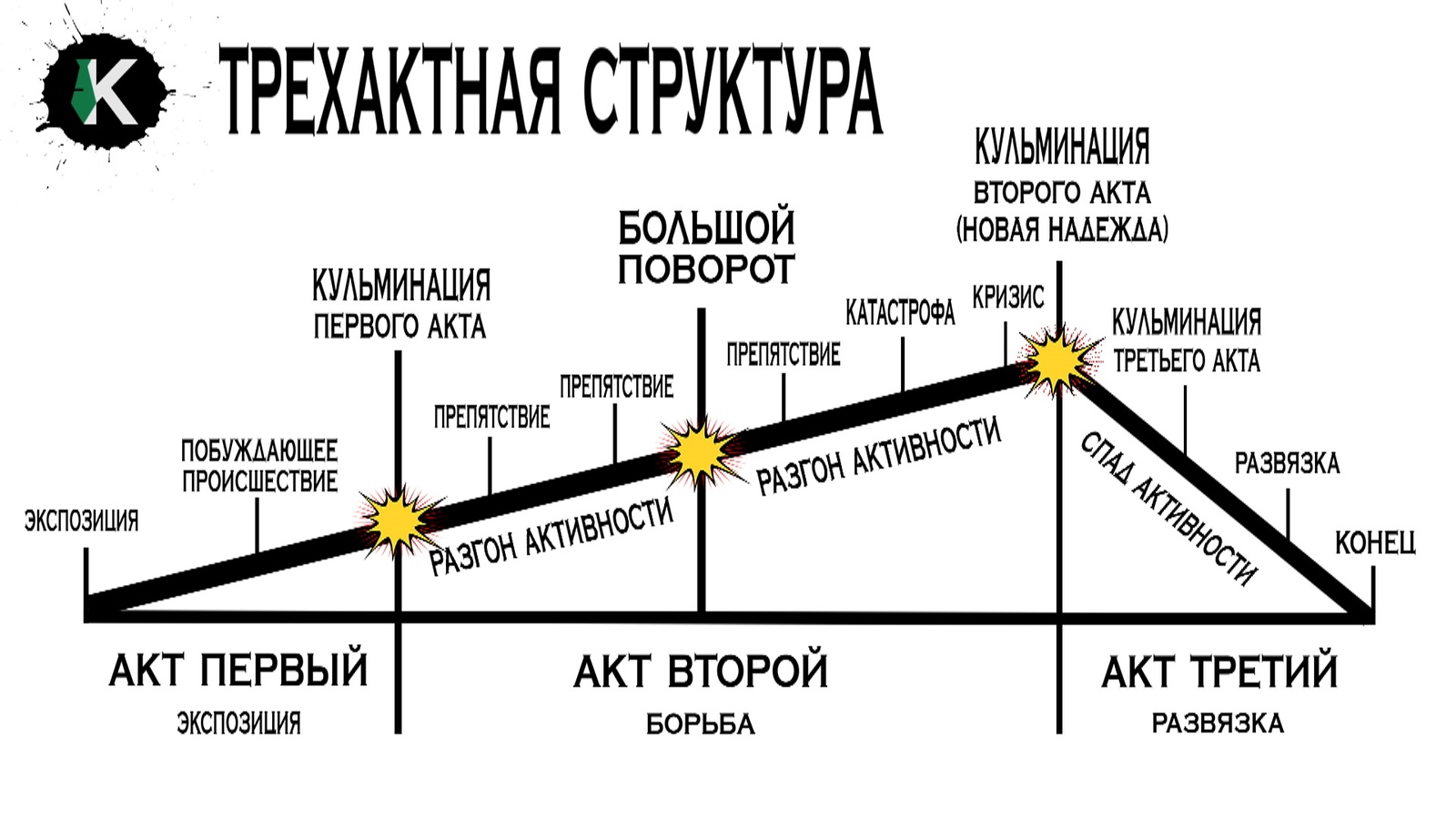
вот этот чувак вещает
Проблемы разрешаются, когда человек начинает понимать, что межличностные конфликты нередко возникают из-за различных способов восприятия мира, а не в следствии эгоцентризма или по злому умыслу.
Карл Густав Юнг, «Психологические типы»
Карл Густав Юнг, «Психологические типы»

Говорят, что утро вечера мудренее. Это действительно так благодаря изменению соотношения норадреналина и ацетилхолина, сопровождающего фазы быстрого сна.
С каждым циклом эмоциональный компонент воспоминаний о произошедшем постепенно исчезает. Наутро мы получаем информацию о событии без дополнительной эмоциональной нагрузки и значительно легче его воспринимаем.
О том, что еще происходит с нами во время сна, сколько спят люди и животные и как регулируются циклы сна и бодрствования, рассказывает сомнолог Михаил Полуэктов: vk-ссыль



Создайте учетную запись или войдите в систему, чтобы комментировать
Вы должны быть участником, чтобы оставить комментарий